All
How to Optimize Your Incident Management Workflow Using Software Solutions

Learn how to optimize your incident management workflow with software for faster, more effective responses.
Incidents, Solutions, and Streamlined Workflows
Imagine a bustling city where every traffic light, road sign, and emergency service is perfectly synchronized, ensuring that even during rush hour, everything flows smoothly. Now, picture what happens when one traffic light fails—chaos, confusion, and delays ripple across the entire system. This is the challenge businesses face when incidents disrupt their operations.
As an integral part of IT Service Management (ITSM) Incident management is the system that keeps everything running smoothly, even when things go wrong. It’s the orchestrated effort that catches issues early, resolves them quickly, and ensures that a minor glitch doesn’t spiral into a major disruption. But like that city’s traffic system, incident management only works well when it's optimized—when every step is aligned, every tool is in place, and every response is as efficient as possible.
In this guide, we’ll explore how you can elevate your incident management process, turning it from a reactive scramble into a well-oiled machine. With the right software and strategies, even the most complex incidents can be handled with ease, ensuring your business keeps moving forward without missing a beat.
Whether you’re new to incident management or looking to refine your approach, this article will walk you through the essentials, helping you create a workflow that’s not just effective but truly optimized.
What Are Some Common Challenges in Incident Management?
Effective incident management is crucial for minimizing disruptions and continuous improvement, but it often comes with its own set of challenges that can hinder swift and efficient resolution. Here are some of the most common obstacles that organizations face:
1. Slow Response Times
When something goes wrong, time is of the essence. However, delays in spotting issues, notifying the right people, or getting the right resources in place can cause slow response times. These delays can turn small problems into big disruptions, leading to more downtime and affecting business operations.
2. Communication Gaps
Good communication is vital for handling incidents effectively. However, in many organizations, breakdowns in communication between teams can cause confusion, repeated work, or unresolved issues. Whether it’s due to a lack of central communication tools or poor coordination, these gaps can significantly slow down how quickly incidents are fixed.
3. Manual Processes
Handling incidents manually can lead to mistakes and slow responses. Relying on manual ways to log, track, and fix incidents can result in missed details, delays, and inconsistent handling of similar issues. This not only slows down how quickly problems are solved but also affects the overall quality of the response.
4. Lack of Visibility and Reporting
Without a clear view of the incident management process, it’s hard to track the status of ongoing issues, spot problems in the workflow, or learn from past incidents. A lack of detailed reports means that organizations and stakeholders miss out on important insights that could help them improve their incident management over time.
5. Inconsistent Incident Resolution
When different teams or individuals handle incidents in different ways, it can lead to unpredictable results. This inconsistency can slow down how quickly problems are solved and may even leave issues unresolved, which can affect service quality and reliability.
How Incident Management Software Addresses These Challenges?
Incident management software tools are designed to solve the common problems that organizations face by simplifying processes and improving efficiency. Here’s how it can help:
1. Automating Incident Detection and Alerts
One of the biggest benefits of incident management software is its ability to automatically spot issues as soon as they happen. The software continuously checks systems and can quickly send real-time alerts to the right teams when a problem occurs. This automation helps cut down the time it takes to find and fix problems, reducing the risk of small issues becoming big disruptions.
2. Centralizing Communication
Clear communication is key to solving incidents quickly, and incident management software brings all communication into one central place. By keeping everyone informed, the software helps prevent misunderstandings and delays that can happen when teams use different tools or channels to communicate. This centralization makes it easier for teams and stakeholders to effectively work together and respond to incidents.
3. Simplifying Workflows
Incident management tools can automate many of the repetitive tasks that slow down fixing incidents. For example, the software can automatically assign tasks, track progress, and enforce standard response steps, ensuring that each incident is handled similarly. This simplification not only speeds up the process but also reduces the chances of mistakes.
4. Better Reporting and Insights
Detailed incident reports and insights are important for understanding incident patterns and finding areas to improve. Incident management software provides complete reports that track the entire incident from start to finish. These insights help organizations learn from past incidents, improve their processes, and make their incident management better over time.
Steps to Optimize Your Incident Management Workflow
Improving your incident management process involves a series of steps designed to make things run more smoothly, reduce downtime, and respond to issues more quickly. Let’s go through these steps with a simple example to show how each one can be put into action.
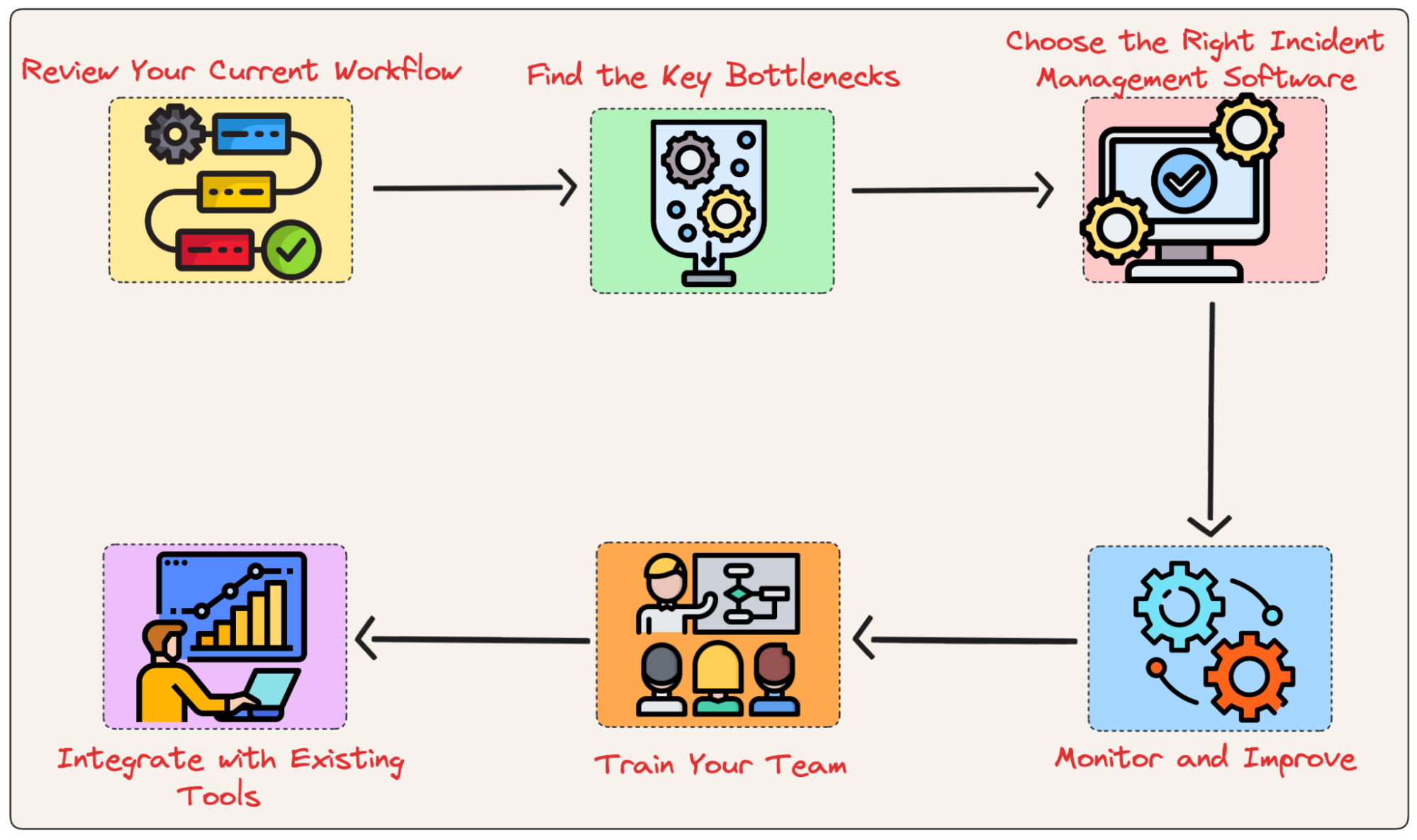
Step 1: Review Your Current Workflow
Before making any changes, it’s important to understand how your current process works. For example, let’s say a company named TechFix currently handles incidents through a mix of email notifications and a basic ticketing system. They notice that some incidents are fixed quickly, while others take days to get attention. By mapping out their workflow, TechFix can see that their process lacks clear prioritization and often relies on manual follow-ups, leading to delays.
Step 2: Find the Key Bottlenecks
Once you’ve reviewed the current workflow, the next step is to find out where things are going wrong. In TechFix’s case, they discovered that the main problem is in the initial sorting of incidents. Without a clear system for prioritizing issues, important problems sometimes get lost among minor ones. Additionally, their reliance on email for communication causes delays when team members miss or overlook messages.
Step 3: Choose the Right Incident Management Software
After finding the bottlenecks, it’s time to pick the right software to solve these issues. For TechFix, they decided to explore options that offer automatic incident prioritization and centralized communication. They look for features like customizable workflows, real-time alerts, and integration with existing tools. They eventually choose a software solution that allows them to filter incidents based on severity and urgency, ensuring that important issues are addressed first.
Step 4: Integrate with Existing Tools
Making sure the new software works well with your current tools is important for a smooth transition. TechFix already uses a project management tool and a monitoring system. The new incident management software connects directly with these tools, pulling in data from the monitoring system to automatically create and prioritize tickets in the project management tool. This integration eliminates the need for manual data entry and ensures that all relevant information is available in one place.
Step 5: Train Your Team
Even the best software is only as good as the people using it. TechFix organizes a series of training sessions for their team to ensure everyone knows how to use the new software. They focus on how to properly log incidents, use the prioritization features, and communicate within the platform. With proper training, the team becomes more confident and efficient in managing incidents.
Step 6: Monitor and Improve
Improvement is an ongoing process. After setting up the new system, TechFix regularly checks how it’s working. They track metrics like response times, incident resolution rates, and team feedback to find areas for further improvement. Over time, they tweak their workflow by adjusting automation rules, refining communication protocols, and adding new features as needed.
By applying these steps to your own organization, you can achieve similar results, ensuring that your incident management workflow is not just functional, but running at its best.
How Have Big Software Companies Implemented Successful Incident Management Workflows
When it comes to incident management, some of the world’s largest software companies have developed highly efficient workflows that allow them to minimize downtime and resolve issues quickly. In this section, we’ll explore how major players like Google, Amazon, and Microsoft manage incidents and how their strategies have helped them maintain reliability and trust.
Google: Automating Incident Response with SRE Practices
Google, one of the most well-known tech giants, relies heavily on Site Reliability Engineering (SRE) principles to manage incidents. SRE at Google involves a combination of software engineering and operations to build and run scalable, reliable systems.
Google Cloud Outage (June 2019)
In June 2019, Google experienced a significant outage that affected its cloud services, including Google Cloud, YouTube, and Gmail. The incident was caused by an internal network failure, which led to cascading effects across multiple services.
Solution:
Google’s SRE teams immediately activated their incident response protocols, which included automated alerting and escalation processes. They used their proprietary incident management tools to centralize communication, assign tasks, and monitor the progress of the resolution. Within hours, the team had identified the root cause—an issue in their network configuration—and implemented a fix. Google also conducted a thorough post-mortem analysis, documenting the incident and the steps taken to resolve it, which was later shared with the public to maintain transparency.
The key takeaway from Google’s approach is the importance of automation and clear communication channels. By automating the detection and alerting processes, Google was able to respond quickly, and by centralizing communication, they ensured that all teams were aligned in their efforts to resolve the incident.
Amazon: Ensuring High Availability with a Decentralized Incident Management Approach
Amazon, another tech giant, has a decentralized approach to incident management, which allows individual teams to take ownership of their services. This approach is essential for maintaining the high availability of services like Amazon Web Services (AWS).
In February 2017, Amazon Web Services (AWS) experienced a significant outage in its S3 service, which affected numerous websites and services across the internet. The issue was traced back to a human error during a routine maintenance task.
Solution:
Amazon’s incident management process began with automatic detection and immediate notification of the outage. Teams responsible for the S3 service quickly identified the issue using their incident management software, which provided real-time data on the health of their systems. They initiated a rollback of the faulty changes and restored service within a few hours.
Post-incident, Amazon reviewed their processes and implemented new safeguards to prevent similar errors in the future, such as better automation of maintenance tasks and additional checks before making changes to critical systems.
Amazon’s decentralized approach allows for faster incident resolution because each team has the autonomy and tools necessary to address issues within their domain. This method, combined with robust monitoring and alerting systems, ensures that incidents are managed swiftly and effectively.
How Documatic Can Help Optimize Your Incident Management
Issue root cause analysis
Documatic helps with finding the root cause of problems by gathering and connecting data from different sources like logs, monitoring tools, and code repositories. This makes it easier for teams to quickly identify what’s causing the problem, rather than just fixing the surface-level issues.
For example, if a server keeps going down, Documatic can help by providing a timeline of recent changes that may have triggered the issue. This allows teams to quickly identify which changes might have caused the problem, leading to faster and more accurate resolutions.
Dependency mapping across multiple codebases when an error occurs
When an error occurs, it’s crucial to understand how different parts of your infrastructure and codebase are interconnected to troubleshoot effectively. Documatic assists by visualizing the infrastructure and code connections across microservices, monorepos, and multiple codebases. This helps developers debug errors as they happen by showing the dependencies and connections, making incident identification easier by pinpointing the source of the issue and reducing the likelihood of additional errors."
Similar issue identification
Documatic helps reduce noise in your tooling by identifying related issues that occur across multiple codebases, services, and over time. By categorizing similar issues, even if they appear in different parts of the system, Documatic allows developers to address recurring problems more efficiently, ensuring that related issues and future incidents are managed consistently across the entire infrastructure.
Bridge call organization
During critical incidents, effective communication and coordination are crucial. Documatic makes it easy to arrange bridge calls, ensuring that the right team members and engineers involved in the triggered event are included. This ensures that all relevant participants are connected and able to collaborate effectively to resolve the issue.
Don’t let critical incidents disrupt your operations—leverage Documatic to enhance your team’s efficiency and ensure swift resolutions. Start your free trial today and experience how Documatic can transform your incident management workflow into a well-oiled machine.
Conclusion and Key Takeaways
In summary, optimizing your incident management workflow with the right software can greatly enhance efficiency, reduce resolution times, and ensure that your team is well-prepared to handle incidents effectively.
By automating key processes, centralizing communication, and continuously refining your approach, you can build a resilient system that minimizes disruptions and maintains smooth operations. Leveraging tools like Documatic can further streamline your incident management, providing robust features that align with industry best practices seen in leading companies like Google and Amazon.