All
Learning from Incidents: How to Conduct a Thorough Post-Mortem

Learn how to effectively manage and learn from software incidents through structured post-mortem processes.
What is Incident Management and Its Steps?
In the software industry, incident management refers to the structured process of detecting, investigating, responding to, and resolving unplanned interruptions that disrupt the workflow.
Such incidents can encompass a wide range of issues, including system failures, hardware malfunctions, service outages, performance degradation, and security breaches.
When it comes to incident management, a swift resolution is crucial to minimize downtime and restore normal operations. While there may be more comprehensive and effective solutions available, the urgency in incident management often requires prioritizing speed over thoroughness, with time being a critical factor in maintaining service continuity.
Having said that, a thorough incident management process would look something similar to this:
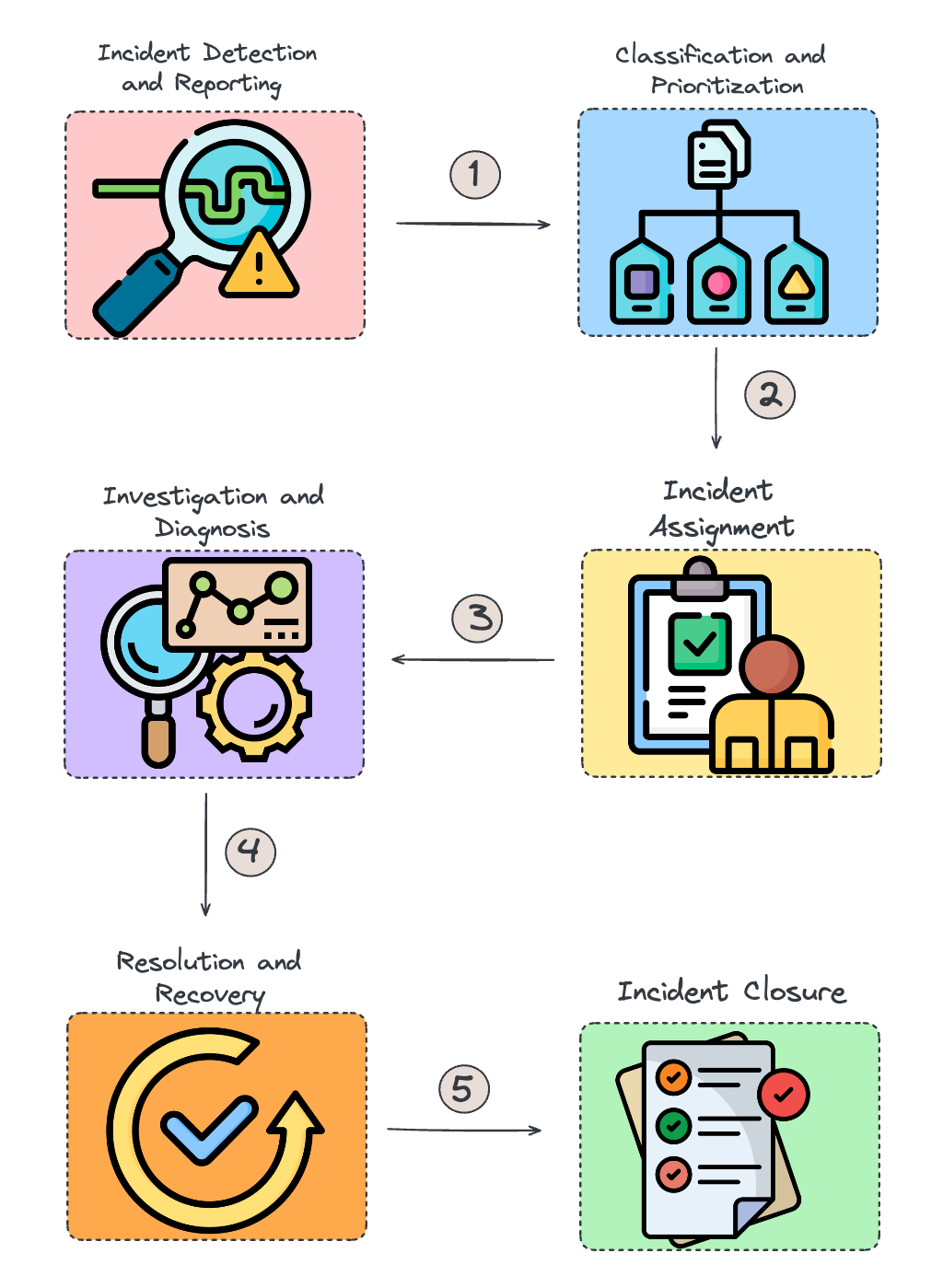
- Incident Detection and Reporting
- How can incidents be detected in real-time? Are there automated tools, logs, and alerts in place to monitor for incidents as they occur? How can users report issues effectively, whether through help desk tickets, phone calls, or emails?
- Classification and Prioritization
- How is an incident classified? What criteria are used to determine if an issue is related to hardware, software, or security? How is the priority level assigned, and what factors influence whether an incident is deemed critical, high, medium, or low?
- Incident Assignment
- Who is responsible for handling the incident? When should an incident be escalated to higher-level support teams or specialized personnel? What determines the need for escalation?
- Investigation and Diagnosis
- What steps are taken to investigate the incident? How is the underlying cause of the problem identified? If a quick resolution isn’t available, what temporary workarounds can be implemented to mitigate the impact?
- Resolution and Recovery
- What changes, patches, or repairs are necessary to resolve the incident? How is the solution tested to ensure it resolves the issue without causing further complications?
- Incident Closure
- How are the details of the incident documented? What information is recorded, including the root cause, resolution steps, and lessons learned? How are affected users informed that the issue has been resolved and that normal service has been restored?
What is an Incident Post-Mortem process?
The Incident Postmortem process is a vital part of the project management process designed to help project teams learn from past incidents. It involves thoroughly documenting every detail of the incident, including its causes, the steps taken to resolve it, and any lessons learned.
By preserving this information, teams can quickly and more effectively address similar incidents in the future. The goal is to continuously improve incident response and prevent recurrence, ensuring a more resilient system.
The incident postmortem process becomes increasingly valuable as our system continues to grow. As systems scale, they often encounter a wider variety of incidents, each with its own complexities.
By conducting thorough postmortems, we can build a robust knowledge base that helps us anticipate and address these challenges more effectively. This proactive approach not only improves our response times but also enhances the overall resilience of our systems, allowing us to maintain stability of projects even as we scale.
Ultimately, a well-executed postmortem process is essential for fostering continuous improvement and ensuring the long-term success of our infrastructure.
Why Should You Follow the Incident Post-Mortem Process? Learning From the Past
The answer is simple: to prevent repeating the same mistakes. Conducting a post-mortem allows us to learn from incidents, understand their root causes, and implement changes that reduce the likelihood of recurrence in future projects.
Moreover, incident post-mortem can proactively identify and prevent potential future issues that haven’t yet occurred. This is possible by refining our processes through a retrospective analysis of previous incidents.
For example, during a post-mortem analysis of a system outage caused by a misconfigured server, the team might discover that the root cause was a lack of standardized configuration procedures. By addressing this underlying issue and implementing standardized practices, they not only prevent the same mistake from happening again but also reduce the risk of similar configuration errors in other areas of the system that could lead to future incidents.
Another crucial aspect of conducting post-mortems is identifying and analyzing the financial impact of incidents at the end of a project. Understanding the financial repercussions allows teams and the organization as a whole to be aware of the potential costs associated with similar future incidents. This financial insight can help prioritize incident response efforts and justify investments in infrastructure improvements or process changes that may prevent costly disruptions.
One important point to consider is that conducting postmortems on less severe incidents allows us to identify and address issues that could potentially cause significant harm in the future and by analyzing and resolving smaller problems early, we can prevent them from escalating into major incidents down the line.
Lastly, it is also crucial to assess whether the incident is a recurring one. If an incident has occurred more than once, follow-up actions become even more important. Recurring incidents indicate underlying issues that have not been fully resolved, and addressing them promptly is vital to prevent occurrences in the next project. Continuous monitoring and review of these incidents should be prioritized to ensure that the solutions implemented are effective and long-lasting leading to project successes in the future.
Key Components of the Incident Post-Mortem Process
Now that we have a better understanding of what Post-Mortem is, and why companies should utilize it, let's dive a bit deeper into the components that build such a process.
- Incident Overview
Summarize the incident, including what happened, when it occurred, and the impact it has had. - Timeline of Events
Detail the sequence of events leading up to, during, and after the incident. - Root Cause Analysis
Explain methods for identifying the underlying causes of the incident. - Impact Assessment
Evaluate the incident's impact on users, systems, and business operations. - Lessons Learned
Recap and document key takeaways and insights gained from the incident. - Action Items and Improvements
List recommended changes or improvements to prevent similar incidents in the future.
How to Handle Your Customers During Incidents?
Having said all that, how can we manage our customers during heavy incidents? How can we establish trust between us and our customers after an unexpected incident?
This process can be divided into two main steps.
The first key point is Proactive Communication. It’s crucial to keep customers informed during an incident. Providing timely updates on the situation, including what happened, what is being done to resolve it, and the expected time for resolution, can help maintain customer trust. Use multiple communication channels, such as emails, status pages, and social media, to reach all affected customers.
The second key point, as you may have guessed is Incident Post Mortem. In order to inform your customer that such an error won't happen again it is crucial to tell them that you learned from your mistakes. This can be done by releasing a minified post-mortem for big clients. Showing the customer what has gone wrong, and how are you planning to handle such an incident again if it ever occurs.
Besides communicating with customers, it's also important to share a smaller, summarized version of the main post-mortem report with the entire organization. This ensures that everyone is aware of what went wrong, how it was addressed, and the steps being taken to prevent it from happening again. This transparency fosters a culture of learning and accountability within the organization, helping to align all teams toward continuous improvement and better agile incident management practices.
Does Incident Post-Mortem Actually Work? Some Real-life Examples
CrowdStrike Incident (July 2024)
In July 2024, CrowdStrike, a leading cybersecurity company, experienced one of the largest IT outages in recent history, affecting Windows machines worldwide. The incident was triggered by a botched update to their Falcon sensor, which is designed to use AI and machine learning to protect customer systems. This update led to widespread "blue screen of death" (BSOD) errors across numerous devices, causing significant disruptions.
The issue was traced back to a Rapid Response Content update deployed on July 19, 2024. This update introduced a mismatch in the expected input fields: the sensor expected 20 fields, but the update provided 21, leading to an out-of-bounds memory read that caused the system crash.
CrowdStrike published an in-depth Root Cause Analysis (RCA) report, acknowledging shortcomings in their testing processes. The company admitted that its standard software development processes failed to catch this critical issue before it was released into production. They highlighted the need for more rigorous testing, including better canary testing (a method where updates are first rolled out to a small, controlled group of devices before a broader release).
Slack Outage (February 2023)
On February 22, 2023, Slack experienced a widespread outage that affected millions of users, preventing them from sending messages, uploading files, and accessing workspaces.
The root cause was a failure in Slack’s database cluster due to an unexpected increase in traffic that overwhelmed the system. This led to a chain reaction of failures across Slack’s infrastructure.
Slack’s post-mortem focused on improving their database scaling mechanisms and implementing more robust traffic management protocols. They also worked on better alerting systems to detect and mitigate such spikes in traffic more effectively.
Some Tools and Resources for Better Post-Mortem Analysis
There are various tools available that can greatly enhance your incident management and post-mortem analysis processes. Tools like Documatic, PagerDuty, and IncidentIO provide features such as automated incident tracking, real-time collaboration, and detailed reporting. These tools help streamline the documentation and analysis of incidents, making it easier to identify root causes and implement improvements.
To maximize the benefits of these tools, it’s important to integrate them seamlessly into your existing incident management workflow. Ensure that all team members are trained on how to use the tools effectively, and establish clear protocols for logging incidents, updating statuses, and documenting resolutions.
Moreover, tailoring the tools to fit the specific needs of your organization. This might include setting up custom incident categories, automating alerts and notifications, and using dashboards to monitor key metrics.
Interested in improving your incident management and post-mortem processes? Start your free trial with Documatic today to automate and streamline your incident tracking and analysis, and see how its powerful features can fit into your workflow.
How to Conduct an Effective Post-Mortem? Some Tips
You must always start by assembling the team. Bring together everyone who was involved in or affected by the incident. This typically includes engineers, managers, stakeholders, and support staff. Ensure all voices are represented to get a holistic view. Remember that different staff members will deal with and be involved with the incident in different ways, a wholesome viewpoint of the incident from all possible angles would always be beneficial. Remember, whatever the cause of the incident was, never throw blame. A no-blame community will always revolve around honesty, which is what is required in a post-mortem analysis.
Moving on, gather all data possible. Collect all relevant information about the incident, including logs, timelines, communications, and any immediate responses. Ensure you have a complete picture of what happened before the meeting. Remember that the more data you collect, the better you will be prepared for the next incident, and even if the data was not useful at this specific point of time, it might be useful at another, so leave nothing out.
In case of holding a post-mortem meeting, the most effective way to handle the meeting, is to start with a review of the incident timeline, when did we first know about the incident, how long did it take us to first respond, when was the incident handled, etc. Assign a moderator to act as the note taker and facilitate moving into discussions around causes and responses. Keep the conversation constructive and solutions-focused. Start with finding the root cause, and then move out to the related points.
Takeaways for Incident Management Success
Handling incidents in the moment can often be challenging and stressful. However, taking the time after an incident to thoroughly review and understand what occurred is crucial for improving future responses. By studying the details and learning from each incident, you equip yourself and your team to be better prepared for similar situations in the future, ultimately leading to more efficient and effective incident management.
