All
The Essential Guide to the Incident Management Process

Learn how to efficiently manage software incidents with actionable steps, tools, and best practices that help minimize downtime and improve system stability.
What is Incident Management?
In software development, incident management is the backbone of maintaining a stable, reliable product. It’s the process of swiftly detecting, diagnosing, and resolving issues that can unexpectedly break an application or service. In the context of IT service management (ITSM) and ITIL frameworks, incident management processes are crucial for everyday IT operations, emphasizing a structured approach to manage incidents effectively, from reporting to resolution. The key goal of such a process is to minimize disruption and get things running smoothly again, ensuring the least possible impact on users and the development pipeline.
Imagine deploying a new feature, only to have the system crash due to an unforeseen bug. The incident management process springs into action—logging the issue, assigning a team to evaluate the problem, and delivering a patch to fix it before it escalates into a bigger mess. This keeps the development flow on track without disrupting the project.
In essence, incident management in software development is like having a fire drill in place—responding swiftly, putting out the blaze, and learning from it to prevent future fires. A well-oiled process ensures not just uptime but ongoing improvement in code quality.
Why Incident Management Matters for Software Development Teams
The main goal of incident management in software development is to maintain the stability and reliability of the application. It’s about responding quickly to any issues that arise, minimizing their impact, and ensuring users face as little disruption as possible. This proactive approach ensures that small problems don’t escalate into major setbacks.
Key objectives include reducing downtime, improving response times, and enhancing communication between teams. By handling incidents efficiently, developers can keep projects on schedule and maintain customer trust. Another objective is continuous learning—each incident is an opportunity to improve processes and prevent similar issues from happening again.
Incident Identification and Logging
Incident identification and logging are the foundational steps in the ITIL incident management process. Recognizing and acknowledging an unplanned interruption or reduction in IT service quality is crucial. This can be reported by employees, customers, or automated monitoring systems. The service desk team plays a pivotal role here, receiving the report and determining whether the issue is an incident or a request.
Once an incident is identified, the next step is incident logging. This involves creating a detailed record of the incident, capturing essential information such as:
- Incident description
- Incident category
- Incident subcategory
- Incident priority
- Incident status
A comprehensive log not only aids in immediate incident resolution but also enriches the knowledge base, helping problem management teams analyze root causes and streamline future incident resolution. Keeping the incident log easily accessible and updated in real-time ensures that all stakeholders have the latest information, facilitating a smoother management process.
How to Spot, Prioritize, and Fix Software Incidents: A Step-by-Step Guide to Managing Software Incidents
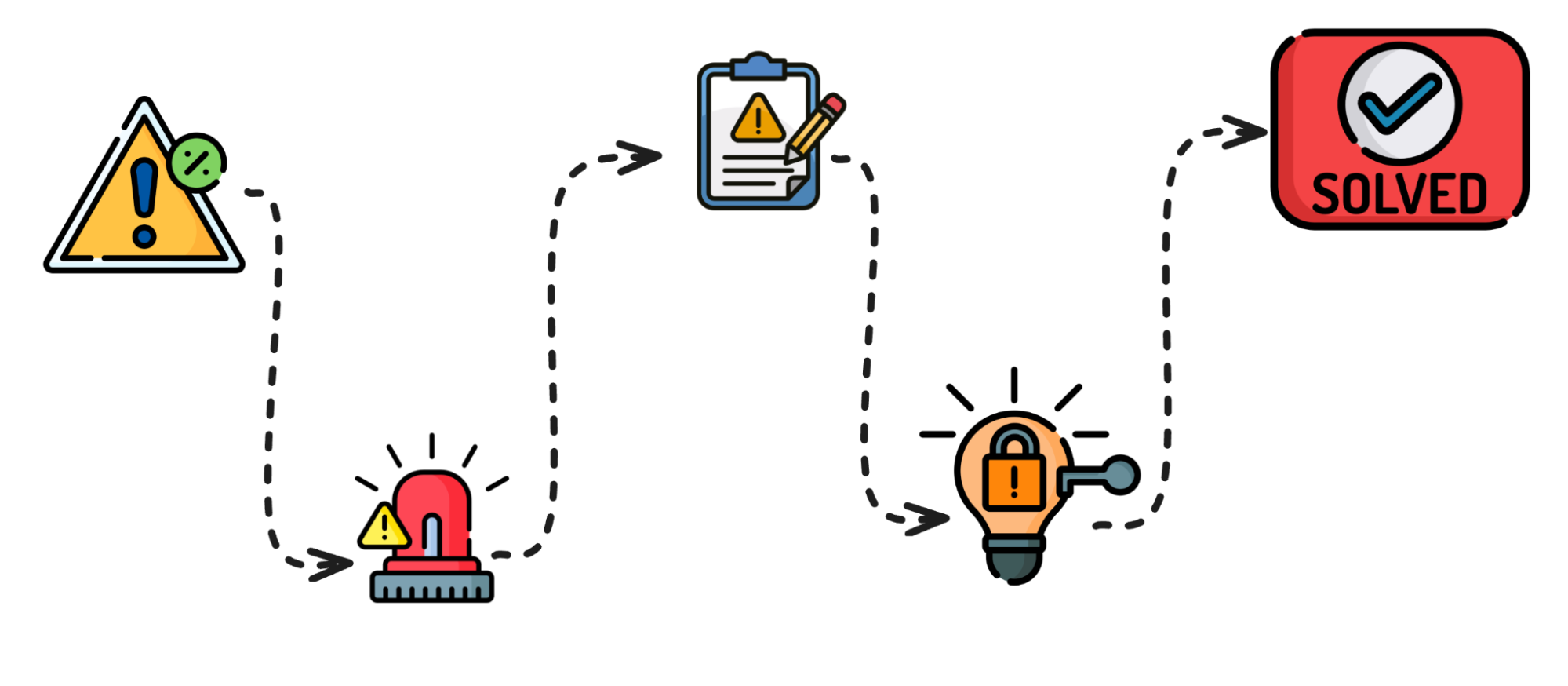
Incident management in software development is a structured approach designed to minimize downtime and ensure issues are handled methodically. Each step in the process plays a crucial role in managing incidents efficiently, helping to restore normal service quickly while preventing future problems. Below is a breakdown of the six key steps involved in such a process.
1. Spotting Issues Early and Keeping the Team Informed
The first step is spotting the problem. Automated tools like system monitors are your best friend—they keep an eye on everything and send alerts as soon as something goes wrong (like a server crashing or a bug causing slow performance). Sometimes, users or employees report issues, so helpdesk systems are essential for capturing these reports and keeping everything organized. Once documented, the details make it easier for the team to jump on fixing things fast.
2. Incident Prioritization: Organizing and Addressing Incidents Based on Impact
After an incident is logged, it’s time to organize and prioritize. You can’t treat all problems the same—some are bigger and more urgent than others. This is where incident prioritization comes into play, assessing incidents based on their impact and urgency. For example, a critical outage that affects hundreds of users is much more urgent than a minor UI glitch. Sorting incidents into categories like “critical” or “low priority” ensures the right teams focus on the most important issues first.
3. When to Investigate and When to Call in the Experts
Once categorized, the support team gets to work. They’ll investigate the issue using logs, tools, and system reports to figure out what’s causing the problem. If the issue is beyond their skills, they escalate it to the experts—either by sending it to specialists or management when big decisions are needed.
4. Digging Deep to Find and Fix the True Problem
When the issue is escalated, the team dives deeper to figure out what’s really going wrong (not just treating the symptoms). This might involve going through system performance data or collaborating with other departments to trace the root cause. This stage often requires teamwork from different areas (like development, infrastructure, and security) to come up with an effective solution.
5. Fixing the Issue and Getting Systems Back Online
Once the root cause is found, the focus shifts to applying the fix—whether it’s a patch, restarting services, or rolling back a bad update. It’s all about getting things back to normal as quickly as possible while ensuring the long-term stability of the system. Recovery is just as important—everything needs to be tested to confirm it’s working smoothly, with no lingering issues.
6. Post Incident Review: Closing the Loop and Learning from Every Incident
When the incident is resolved, it’s not over yet. Incident closure is the final step where the service desk verifies that the issue is resolved and the user is satisfied before formally closing the ticket. You need to close the loop by verifying everything is fixed and no further problems exist. A post-incident review helps the team analyze what happened, how it was handled, and what could be improved. This helps ensure future incidents are managed even better, refining your process over time.
Major Incident Management
Major incident management is a critical component of the incident management process, focusing on high-impact, high-urgency incidents that affect a large number of users and disrupt crucial business services. The primary goal here is to minimize business impact and expedite incident resolution.
A well-defined major incident management process typically includes several key phases:
- Communication Planning: Establishing communication plans tailored to the type and priority of the incident, as well as the target audience.
- Incident Notification and Status Updates: Keeping stakeholders informed with timely notifications and status updates throughout the incident’s life cycle.
- Post-Incident Reporting: Once the incident is resolved, creating a detailed post-incident report. This report is reviewed and updated during the post-incident review process before being shared with stakeholders.
Handling major incidents requires a structured approach to ensure efficiency and effectiveness. This involves defining clear roles and responsibilities, establishing robust communication channels, and having a well-documented process for incident resolution and post-incident review. Such a structured approach ensures that major incidents are managed with minimal disruption to business operations.
Common Pitfalls in Incident Management
Handling incidents efficiently can be tough, especially when common challenges get in the way. Here are some of the key hurdles teams often face, and how they can impact the process.

- Lack of Proper Documentation: When incidents aren’t properly documented, important details can be missed, leading to slower resolution times. Without a clear log of what happened, teams can struggle to find the root cause, slowing down the resolution process and increasing the chances of the same issue reoccurring.
- Poor Communication: If teams don’t communicate effectively during an incident, confusion sets in. Without clear updates, people can be left guessing what’s happening, leading to frustration and delayed fixes. Keeping everyone in the loop is essential to smooth out the process.
- Misclassification of Incidents: Not all incidents are created equal. Mislabeling a critical issue as a minor one can lead to long delays in fixing major problems. Properly categorizing incidents ensures that the most serious ones get the attention they need right away.
- Resource Constraints: Sometimes there just aren’t enough people or the right tools to tackle an incident quickly. This shortage of resources can turn a simple problem into a drawn-out issue, with teams scrambling to get things back on track.
- Lack of Standardization: Without a clear, consistent approach, different teams might handle incidents in their own way, leading to inefficiencies. Having standardized procedures ensures everyone is on the same page, speeding up the resolution.
6 Essential Strategies for Efficient Incident Resolution
Managing incidents well isn’t just about fixing problems—it’s about doing it efficiently and learning from the process. Here are six best practices to keep things running smoothly:
- Clear Communication: When something breaks, everyone needs to know what’s going on. Think of it like updating your team during a fire drill. Keeping stakeholders in the loop helps prevent chaos and confusion.
- Effective Documentation: Every step of the incident needs to be written down. This isn’t just for record-keeping—next time, when something similar happens, you’ll know exactly how to handle it. It's like keeping a recipe book for fixing problems.
- Use of Automation: Let the robots help! Tools can be used in order to detect issues early and automatically log incidents. This speeds up the process so you’re not scrambling to find the problem yourself.
- Cross-Departmental Collaboration: Sometimes, fixing an incident requires more than just the dev team. Bring in IT, cybersecurity, or even business teams for a full-picture solution.
- Continuous Improvement: After resolving an incident, have a quick debrief. What went well? What didn’t? It’s like reviewing game tape after a match to up your skills.
- No Blame Culture: Mistakes happen—what matters is how you learn from them. Encourage an environment where people feel safe admitting errors, so the team can focus on solving the problem, not pointing fingers.
The Best Tools to Optimize Your Incident Response
A solid incident management process starts with effective monitoring tools and seamless collaboration platforms. Tools like Datadog, Prometheus, and Grafana play a crucial role in incident detection by providing real-time system monitoring and alerting. These platforms keep an eye on key performance metrics—like CPU usage, memory consumption, and application response times—and trigger alerts when something goes wrong. This proactive approach ensures that potential issues are caught early before they escalate into major incidents.
When an incident occurs, communication tools like Slack or Microsoft Teams become indispensable. Integrated with incident management platforms like Documatic or Opsgenie, they enable cross-departmental collaboration by allowing engineers, IT teams, and management to communicate instantly. Whether it's sharing updates, logs, or diagnostic data, having a unified communication channel reduces the risk of delays or miscommunication during an incident. This coordinated approach speeds up the response process and minimizes downtime.
By combining robust monitoring with seamless collaboration, teams can stay ahead of incidents and ensure they are resolved swiftly with minimal disruption.
Documatic: The Future of Incident Management
Documatic takes incident management to the next level by integrating directly with your codebase and DevOps tools. Unlike traditional incident platforms, Documatic excels at correlating incidents with code issues, allowing developers to pinpoint the root cause quickly, reducing the time spent on manual troubleshooting.
Ready to streamline your incident management process? Start a free trial with Documatic today and experience faster, smarter incident response.
Key Takeaways for Handling Incidents with Confidence
Managing software incidents doesn’t have to be overwhelming. By following a structured process—spotting issues early, prioritizing incidents, and collaborating across teams—you can minimize downtime and keep systems running smoothly. By learning from each incident and continuously improving your process, you’ll be better equipped to handle future problems efficiently. Keeping things simple, makes incident management a smoother process overall.