All
How AI is Revolutionizing Incident Management

Discover how AI is revolutionizing incident management by enabling real-time detection, root cause analysis, predictive analytics, and automated resolution across complex infrastructures.
Why is Incident Response Important?
Incident response is a critical component of an organization’s overall cybersecurity strategy. It refers to the process of identifying, containing, and mitigating the effects of a security incident, such as a data breach or a ransomware attack. Incident response involves a combination of people, processes, and technology to detect and respond to security incidents in a timely and effective manner. The goal of incident response is to minimize the impact of a security incident on an organization’s operations, reputation, and bottom line.
Rethinking Incident Management for Complex Systems with an Incident Response Team
Today’s systems have evolved into highly complex, interconnected networks, with architectures built on microservices, hybrid cloud environments, and edge computing. Consider a large e-commerce platform like Amazon, where thousands of microservices handle everything from customer orders to inventory management and payment processing. These services are distributed across multiple data centers and cloud providers, making incident detection and resolution a monumental challenge. Traditional incident management tools struggle to provide the real-time visibility and coordination required in such environments, often leading to delayed responses and prolonged downtime. Incident response frameworks, such as those from NIST, ISO, and SANS Institute, offer structured guidelines that can help organizations develop effective Incident Response Plans (IRP) to manage these challenges.
Manual incident management approaches can become overwhelming when dealing with complex infrastructures like Netflix’s. Netflix, with its microservices architecture composed of over 1,000 services distributed across various cloud environments, faces significant challenges when a service failure or a security event occurs. Identifying the root cause in such a system often requires tracing through a web of interconnected dependencies. There have been instances where Netflix engineers spent considerable time investigating degraded streaming quality, only to trace the issue back to a single failing instance in their backend. Traditional incident management tools struggled to handle the complexity of tracking down issues in such an extensive network of services.
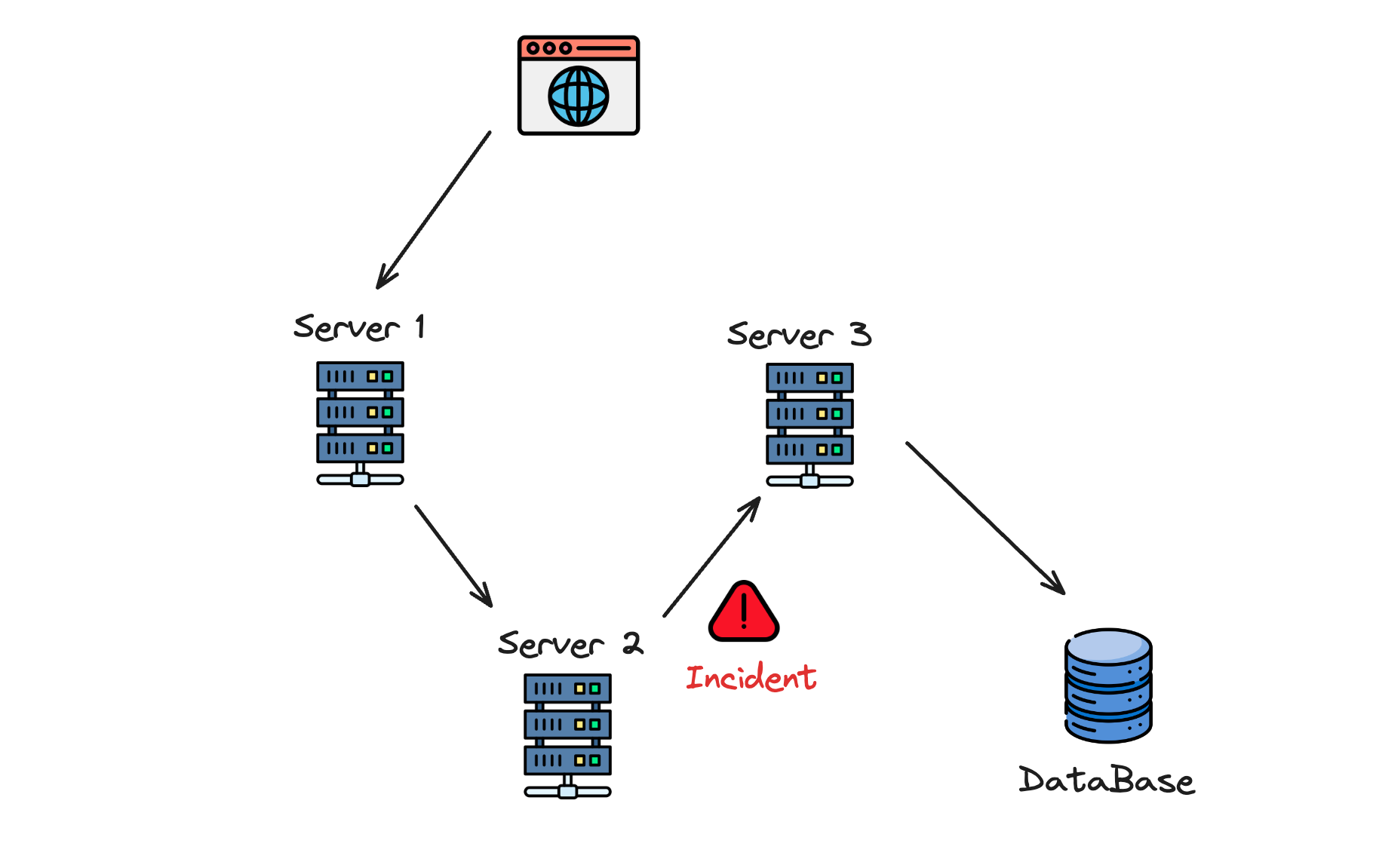
AI-driven incident management systems can revolutionize how organizations handle such complex environments. For example, Uber uses machine learning algorithms to monitor their microservices infrastructure. Their AI system analyzes logs, metrics, and performance data in real-time, detecting anomalies before they impact users. Incident response tools play a crucial role in these AI-driven systems by facilitating visibility, threat analysis, and automated processes. When a service failure occurs, the system automatically identifies the root cause and provides recommendations for remediation. This reduces incident resolution times from hours to minutes, keeping services running smoothly even in intricate, large-scale environments. Incident response services also provide 24/7 support and develop tailored incident response plans, aiding in real-time detection and crisis management.
Incident Response Lifecycle and Planning
The incident response lifecycle consists of several phases, including preparation, detection, containment, eradication, recovery, and post-incident activities. Preparation involves developing an incident response plan, identifying incident response team members, and establishing communication protocols. Detection involves identifying potential security incidents through monitoring and analysis. Containment involves isolating the affected systems or data to prevent further damage. Eradication involves removing the root cause of the incident, such as malware or a vulnerability. Recovery involves restoring systems and data to a known good state. Post-incident activities involve reviewing the incident, identifying lessons learned, and implementing changes to prevent similar incidents in the future.
Building an Effective Incident Response Team
An effective incident response team, also sometimes known as the computer emergency response team consists of individuals with diverse skill sets and expertise. These incident response teams should include an incident response manager, security analysts, technical experts, and communication specialists. The team should be trained and equipped to respond to security incidents in a timely and effective manner. The incident response team should also have a clear understanding of their roles and responsibilities, as well as the incident response plan and procedures.
Understanding Security Incidents
Security incidents can take many forms, including unauthorized access to systems or data, malware outbreaks, denial-of-service attacks, and data breaches. Understanding the types of security incidents that can occur is critical to developing an effective incident response plan. Organizations should also be aware of the potential impact of a security incident on their operations, reputation, and bottom line.
How Does AI Enable Smarter Incident Detection in Multi-Cloud Environments?
AI’s real-time anomaly detection is well-suited for managing hybrid and multi-cloud environments, where systems are spread across different platforms, such as Azure, Google Cloud, and AWS. It adapts quickly to changing conditions, identifying issues in decentralized environments that static monitoring tools might miss. Additionally, AI enhances threat detection across multi-cloud environments by integrating various tools and techniques to create a holistic security ecosystem.
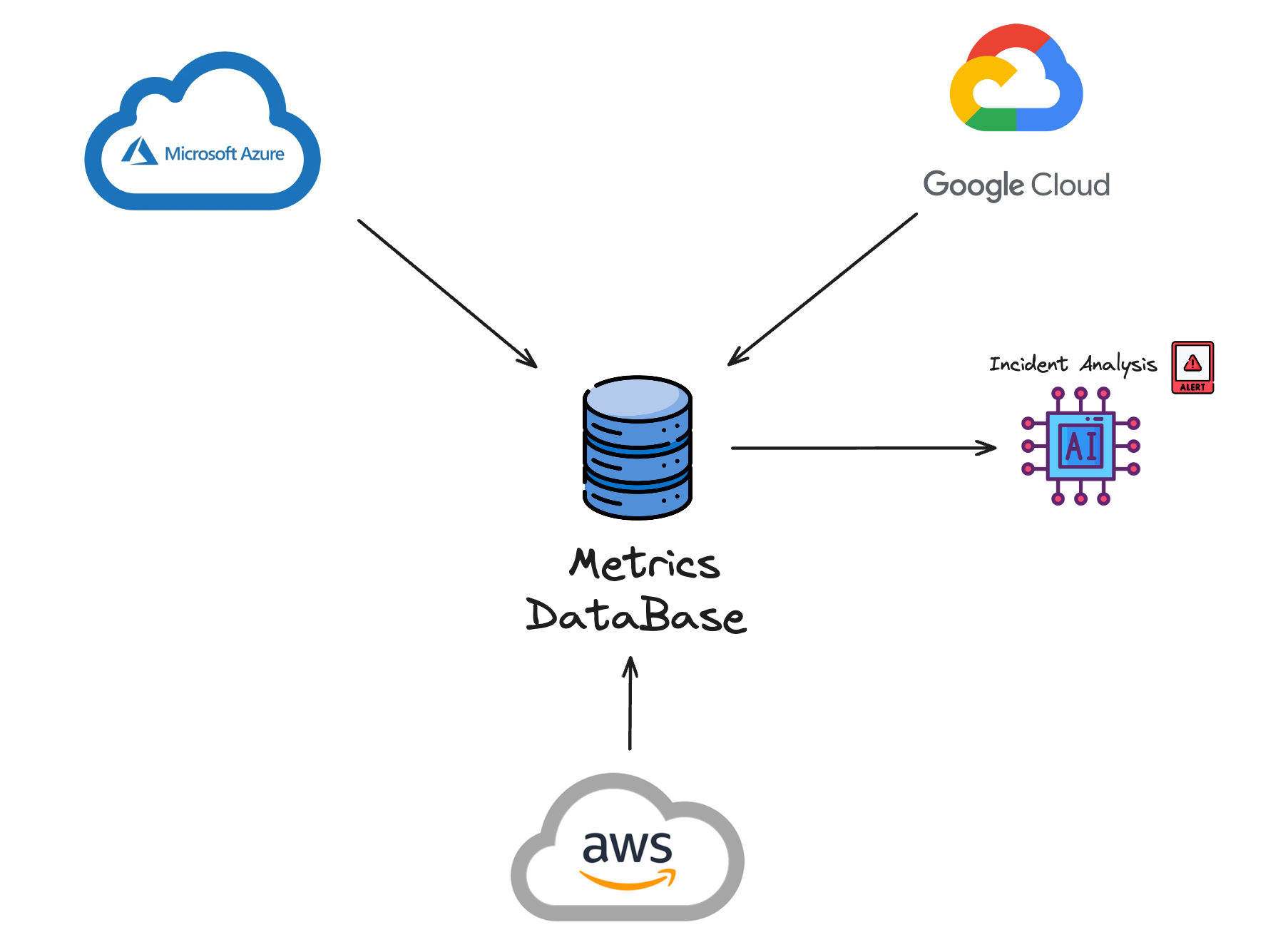
AI improves incident management by seamlessly integrating data from various cloud platforms. This unified approach allows faster, more accurate detection and resolution, unlike traditional tools that struggle to manage multiple environments efficiently. By leveraging AI, companies can optimize performance and streamline incident detection across
Unlike traditional methods that rely on fixed thresholds, AI can also utilize historical data and real-time metrics to detect subtle, emerging issues. This allows for the early detection of anomalies and accurate risk assessment, even in complex, dynamic systems.
How Does AI Uncover Root Causes in Distributed Systems?
AI excels at tracking incidents across various layers of a distributed system, from microservices to databases and external APIs. It automatically correlates events across these components, analyzing vast amounts of log data and metrics to pinpoint the root cause of an issue. This reduces the time engineers spend manually sifting through multiple layers of a tech stack to find the source of a problem.
In multi-tier applications, failures can involve multiple components, such as an app server, database, or third-party services. AI-driven root cause analysis allows organizations to diagnose these failures quickly by correlating issues across different layers. For example, if an app server crash is caused by an external API performance bottleneck, AI can trace the issue through logs, metrics, and dependencies, providing actionable insights.
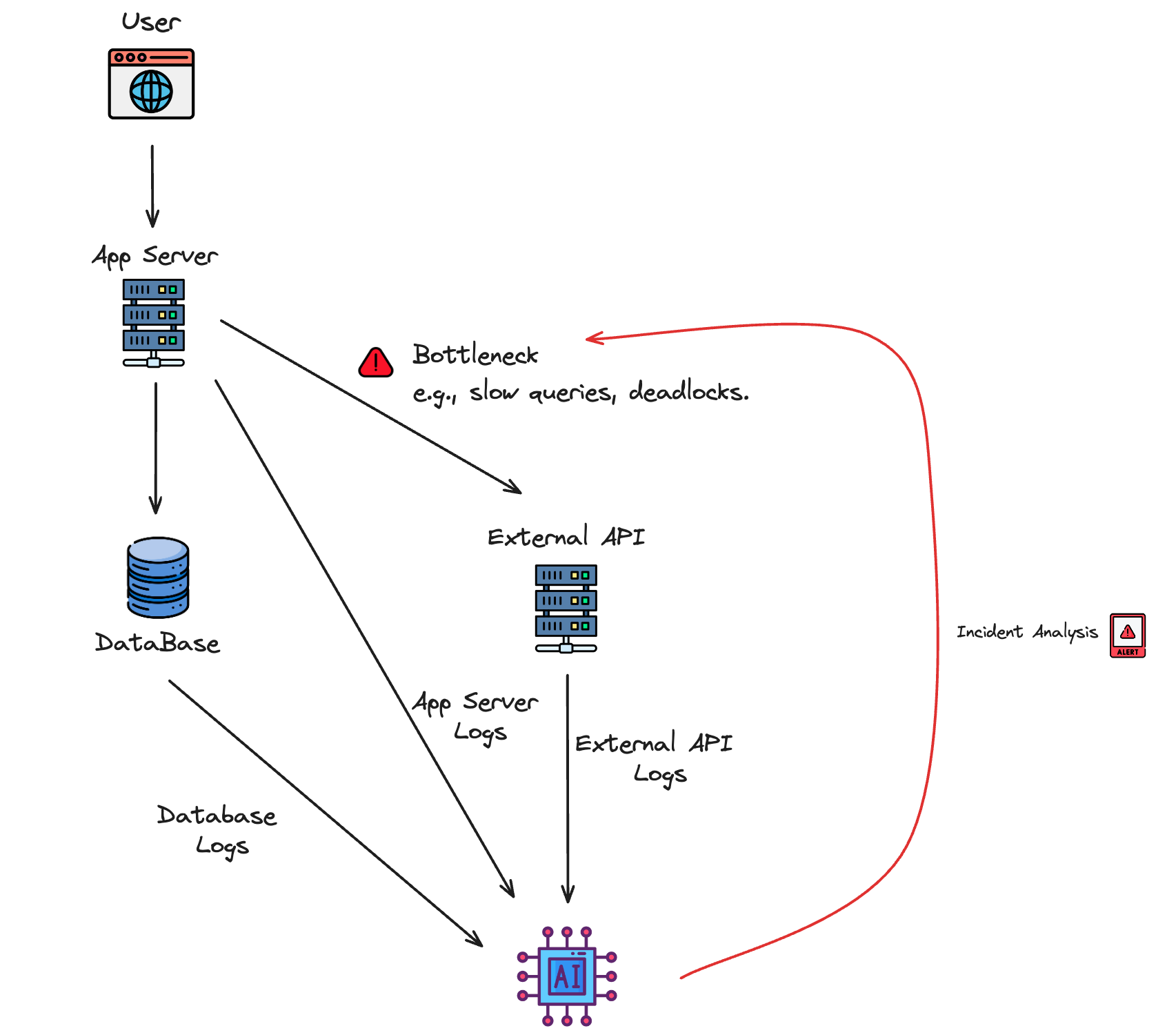
In a large SaaS environment, an AI-driven root cause analysis tool could help resolve complex incidents involving third-party payment gateways. For example, if the platform experienced transaction failures that appeared to stem from the app's payment module, AI could identify the true issue, such as a rate-limiting error in the third-party service API. By tracking performance metrics and API response patterns, the system would enable the engineering team to resolve the issue swiftly, minimizing downtime and user impact.
How Can Predictive Analytics Help Prevent Incidents Before They Happen?
Predictive analysis in this context aims to catch errors before they even occur. While traditional, non-AI incident management tools allow setting thresholds for failures—such as 95% CPU utilization—they primarily focus on enhancing incident resolution once an issue arises. However, these tools are not designed to prevent incidents from happening in the first place. This is where AI and predictive analysis play a crucial role, as they can foresee potential future issues.
AI uses historical data patterns to predict potential incidents before they occur. By analyzing past incidents, trends, and anomalies in real-time, AI models can foresee issues that are likely to emerge. For example, in IT operations, predictive analytics can flag patterns that resemble past system failures, allowing teams to address vulnerabilities before they result in downtime. This proactive approach helps minimize the impact of outages and ensures smoother operations.
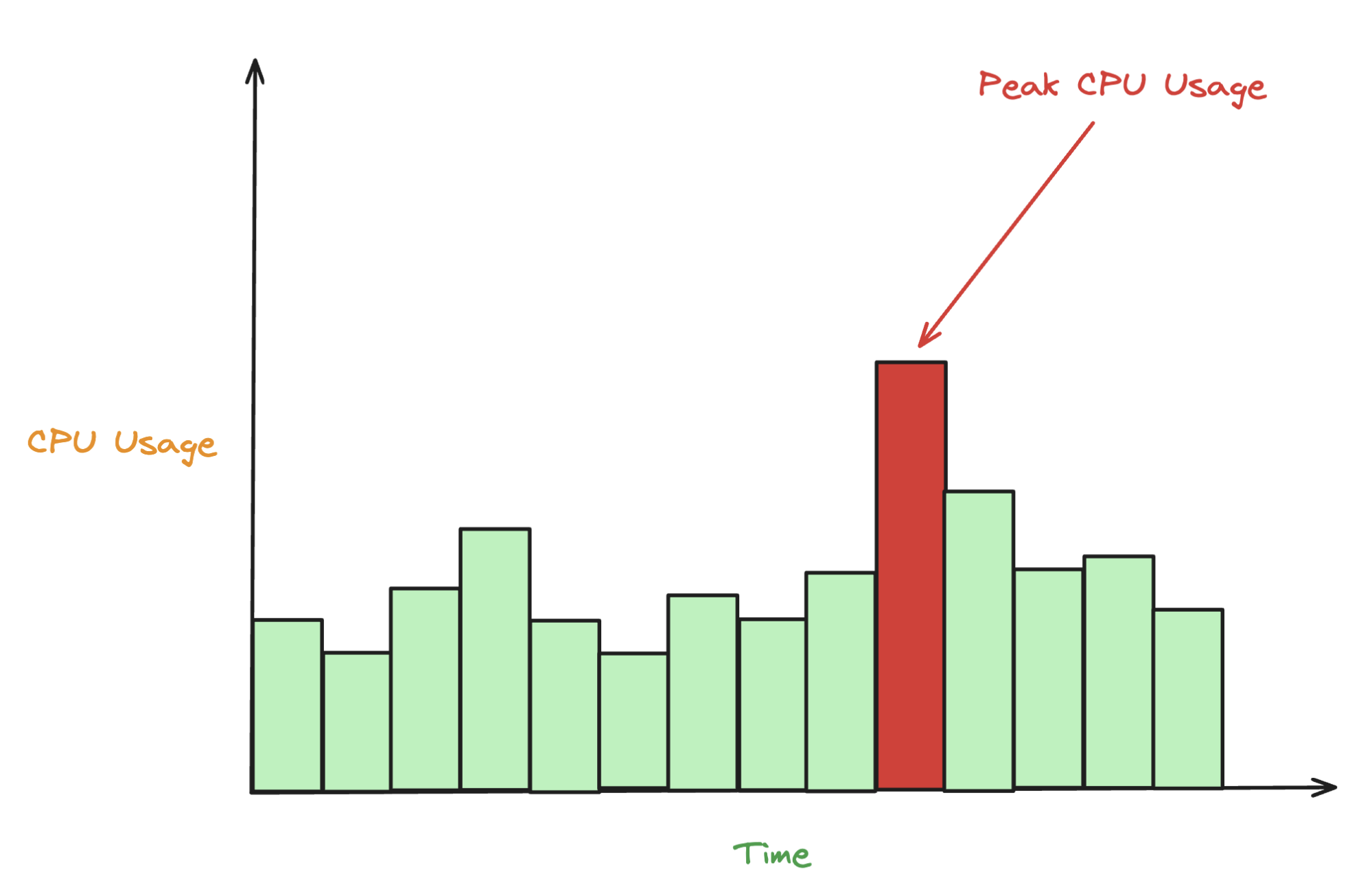
In this given example, the system has been monitoring CPU usage over time. By analyzing historical performance data and identifying trends, the AI model can flag anomalies—like the peak CPU usage shown in red—as early warning signs of potential system degradation or failure.
When CPU usage suddenly spikes beyond normal thresholds (as shown in the graph), it could indicate issues such as:
- A resource-intensive process running unexpectedly.
- Memory leaks or hardware malfunctions.
- A misconfigured application.
The AI model, trained on past incidents where similar spikes led to system crashes or slowdowns, would predict this as an impending issue. Teams could be alerted in advance to take corrective action (e.g., scale up resources, restart processes, or find the unexpected resource-intensive processes), avoiding potential downtime or service degradation.
AI Incident Response Tools Transforming Incident Management
AI-powered operations tools are reshaping how enterprises manage incidents across complex infrastructures. Platforms such as Documatic go beyond traditional alerting mechanisms offering root cause analysis, dependency mapping across multiple codebases, similar issue identification, and even automated resolution. When an error occurs, Documatic quickly identifies the root cause, maps dependencies across your entire codebase, and flags similar past issues, allowing your team to resolve problems faster and more effectively.
Ready to transform your incident management process? Explore how Documatic can enhance your infrastructure with AI-driven precision and reliability. Get started with Documatic’s Free Trail today to prevent issues before they impact your business.
Modernizing Incident Management Systems
Modernizing incident management systems involves implementing new technologies and processes to improve incident detection, response, and resolution. This can include implementing automated response tools, such as security orchestration, automation, and response (SOAR) platforms, and leveraging artificial intelligence and machine learning to improve incident detection and analysis. Modernizing incident management systems can also involve implementing new communication protocols, such as collaboration tools and incident response platforms, to improve communication and coordination among incident response team members.
Conclusion
AI plays a critical role in helping organizations maintain system resiliency and operational efficiency by automating key aspects of incident management. From preemptive detection of issues to real-time root cause analysis and automated response, AI-powered tools enable enterprises to handle increasingly complex infrastructures. By reducing manual intervention and accelerating response times, AI ensures minimal downtime and optimized performance, which is crucial in today’s fast-paced digital environments.
What might the next steps for the industry adoption be? For industry leaders, the next logical step is to embrace AI-driven incident management solutions. Integrating these tools into existing DevOps pipelines will ensure continuous optimization, allowing businesses to predict and prevent incidents before they impact operations. By adopting AI-powered AIOps platforms, organizations can scale their operations efficiently and stay ahead in an increasingly competitive market.